A First Look at Topic Modeling for the Translation Dataset
To better understand the content of the translation dataset, I’ve conducted some basic topic modeling. The dataset used is the English portion of the sentence pairs in ‘openpecha/cleaned_MT_v1.0.2’
Please note that I can only provide a limited number of links and images. If you would like additional information or copies of the other visualizations produces, please don’t hesitate to reach out by email at billingsmoore [at] gmail [dot] com.
Executive Summary
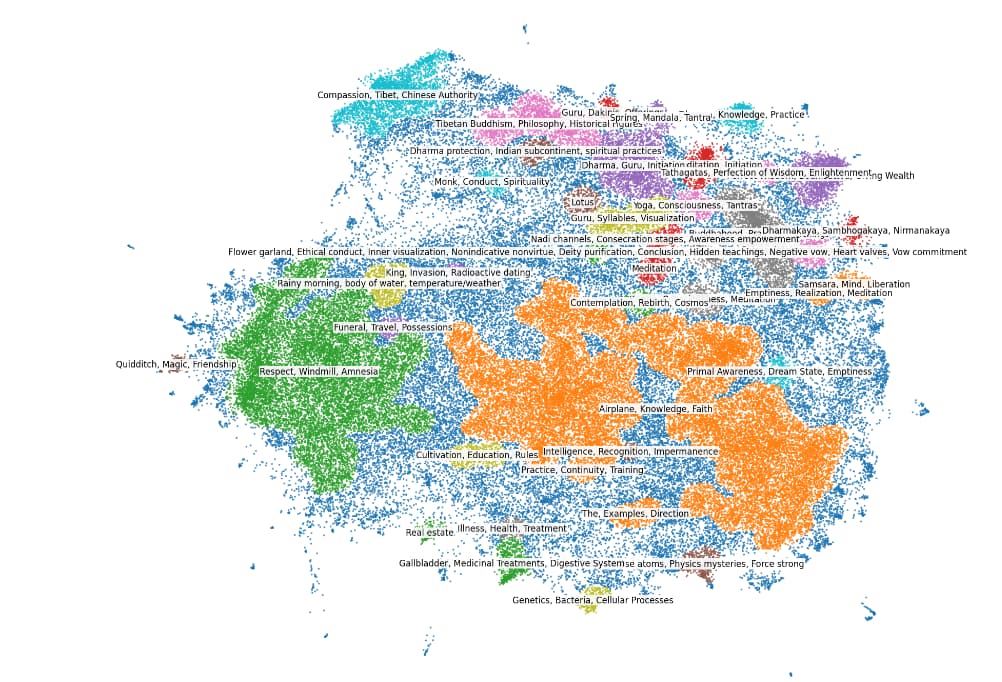
Initial experiments on random samples of 100,000 texts suggest that the ideal clustering algorithm for this dataset is in the DBSCAN family. The most informative visualization was produced using a minimum cluster size of 150 samples and an epsilon of 0.15. This visualization is presented below. Note that there are clear cluster along the bottom edge that are clearly from academic and business-oriented sources. On the far left edge, texts from the Harry Potter novel series are visible. However, the overwhelming majority of texts appear to be from Buddhist sources. The expectation is that the dataset at large will contain similar proportions.
Methods
The pipeline used is based on ‘huggingface/text-clustering’ but was implemented using my fork of the that project which I have altered by allowing for the use of multiple clustering algorithms with user-specified hyperparameters. Documentation for that fork is a work in progress.
Pipeline
As noted above, randomized sets of 100,000 English sentences were extracted from the ‘cleaned_MT_v1.0.2’ dataset. These sentences were embedded as vectors using 'sentence-transformers/all-MiniLM-L6-v2
These embeddings were projected into two-dimensions using UMAP.
The two-dimensional data was then clustered using three clustering algorithms: ‘K-Means’, ‘OPTICS’, and ‘DBSCAN’.
A random set of 10 samples from each cluster were then fed to “mistralai/Mixtral-8x7B-Instruct-v0.1” for summarization using the following prompt: “Use three words total (comma separated)to describe general topics in above texts. Under no circumstances use enumeration. Example format: Tree, Cat, Fireman”
The clusters and the summary labels were then plotted using Plotly.
Experiments
Three clustering algorithms were tried to explore different approaches: ‘K-Means’, ‘OPTICS’, and ‘DBSCAN’.
KMeans
KMeans clustering was tried with the following numbers of clusters: 5, 10, 15, 20, and 25.
In general, at small numbers of clusters KMeans produces clusters that fail to be meaningful, while at larger numbers of clusters the clusters overlap significantly in semantic content. This indicates that true clusters in the dataset are not of equal (or close to equal) size, thus motivating the move toward OPTICS or DBSCAN.
OPTICS
OPTICS clustering was tried at the three sizes for minimum samples per cluster: 50, 100, and 150.
In general, OPTICS unhelpfully marks the majority of the data as noise. However, it helpfully shows small, dense clusters of data from Harry Potter and scientific sources. This indicates that most of the data is relatively similar, with small pockets of data which deviate significantly from that norm.
DBSCAN
DBSCAN was tried at three values of minimum sample size: 100, 150, and 200; and at four sizes of epsilon: 0.1, 0.12, 0.15, and .2.
In general, small sample sizes and small epsilon values produced extremely large numbers of extremely small clusters, with large values tending to create larger, more informative clusters. In the interest of brevity, only a handful of the most informative visualizations are presented below:
Conclusion
We can see in the visualization above that the data is distributed very unevenly, with the vast majority of samples coming from Buddhist sources. Only a minority of data appears to come from other sources, namely: Harry Potter, scientific articles, business and finance writing, and medical information.
Next Steps
Currently, I am working to reproduce this process on the full translation dataset. It is expected that it will exhibit a proportions. I intend to then sort out the non-Buddhist texts in order to produce a more fine-grained topic model of the Buddhist sources.