Pecha API Product Requirements Document ( PRD ) Template
 Purpose and Demographic
Purpose and Demographic
The purpose of the Pecha API is to store and standardize Buddhist data—including texts, audio, and images—along with their annotations and metadata. The data can come from publicly available sources, collaborations with organizations, OCR-generated content, or user-submitted materials. Once standardized, this data will be made freely accessible through our APIs. We believe this resource will contribute to significant advancements in areas such as Buddhist practice, academic research, and AI development.
✦ Mission Statement
Given the variety of data sources, we will develop dedicated parsers within our Toolkit package. These parsers will convert incoming data—with rich annotations—into our standardized OPF format, which is internally structured using the STAM format. For contributors wishing to add their own data, we will provide comprehensive documentation to guide them in adhering to our format.
All data in the OPF format will be stored in our Google Cloud Storage with proper versioning. This data will be accessible through our REST API, ensuring open and easy access for anyone who wishes to use it.
✦ Target Demographic
-
Researchers and Academics: Scholars, linguists, and students involved in Buddhist studies, comparative religion, Asian studies, and digital humanities who require standardized, high-quality data for analysis and publication.
-
Translators and Annotators: Professional and volunteer translators, along with annotators, who rely on parallel versions of texts for comparative study, accurate translation, and scholarly commentary.
-
Monastic Communities and Practitioners: Buddhist monks, nuns, and lay practitioners who seek reliable access to traditional texts for study, teaching, and spiritual practice.
-
AI and NLP Engineers: Developers and researchers working on Tibetan and Sanskrit language models, OCR systems, and other AI tools who need well-structured and annotated training data.
-
Archivists and Librarians: Professionals working in libraries, museums, and cultural heritage institutions interested in preserving and providing access to historical Buddhist texts.
-
Open Source and Digital Humanities Contributors: Technologists and contributors focused on digital preservation, cultural heritage, and the creation of open scholarly resources.
✦ Problem Statement
-
Buddhist texts, audio, and image data exist in a wide range of formats, often inconsistent and unstructured, making it difficult to access, analyze, and reuse them effectively. There is a clear need for a standardized format to uniformly represent this data across various sources.
-
In addition to the data itself, storing rich annotations is essential for scholarly research, translation efforts, digital applications, and AI development. However, such annotations are often lacking or fragmented.
-
As more data becomes available, mapping relationships—such as versions, translations, commentaries, and other connections—becomes increasingly important. Capturing these relationships is crucial for improving data quality and enabling advanced AI applications.
-
While some datasets exist, they are not always easily accessible or freely usable. There is a pressing need for a platform that not only standardizes and annotates this data but also makes it openly accessible through a reliable, well-documented API for researchers, practitioners, and developers alike.
 Product Objectives
Product Objectives
✦ Core Objectives
-
Data Processing and Standardization: Develop and maintain parsers to handle data from a wide range of sources. Ensure all data is converted into the OpenPecha format, with consistent structure.
-
Comprehensive Annotation and Metadata Storage: Support and store various types of annotations (e.g., segmentation, footnote, pagination) along with detailed metadata. This ensures the data is not only preserved but also enriched for academic, religious, and technical use cases.
-
Accessible and Well-Documented APIs: Provide robust, well-documented APIs that allow users to programmatically access texts, annotations, and metadata. Emphasize ease of use, stability, and transparency.
-
Comprehensive Documentation: Create and maintain clear, detailed documentation covering all components of the system—including the Toolkit, API, data formats, and backend infrastructure—to ensure accessibility, collaboration, and long-term maintainability.
✦ Non-Goals
-
Data Model Customization: We will not customize or modify our data model to accommodate specific requirements from third-party products using our APIs. Instead, we maintain a platform-agnostic approach, allowing other products to adapt our standardized data to their own systems.
-
Editorial Authority: While we collect and preserve different versions of texts, we do not determine which version is “best” or most authoritative. Our purpose is to make these diverse texts accessible and available for comparison. We believe the scholarly community will naturally develop consensus about textual quality and authenticity over time.
✦ Impact Areas
-
Academic Institutions: Universities and research centers studying Tibetan Buddhism, comparative religion, and Asian studies will gain access to comprehensive textual resources for scholarly research and curriculum development.
-
Digital Humanities Projects: Existing digital humanities initiatives can integrate our standardized data to enhance their text analysis, linguistic research, and cross-cultural studies.
-
Translation Communities: Professional and volunteer translator networks will benefit from access to multiple text versions for comparison and reference, improving translation accuracy and scholarly rigor.
-
Buddhist Monasteries and Centers: Traditional religious institutions can utilize the platform to access authentic texts for teaching, study, and preservation of their literary heritage.
-
AI and Machine Learning Research: Researchers developing language models, OCR systems, and natural language processing tools for Tibetan and Sanskrit texts will have access to high-quality training data.
-
Open Source Ecosystem: The broader open-source community focused on cultural preservation and digital archives will benefit from our standardized data formats and API infrastructure.
-
Publishing Industry: Academic publishers and digital publishing platforms can leverage our APIs to enhance their Buddhist studies publications with verified textual references.
-
Library and Archive Systems: Digital libraries and cultural heritage institutions can integrate our data to expand their collections and improve discoverability of Buddhist texts.
 Example Use Cases
Example Use Cases
✦ Pecha Study Platform
Pecha connects users to Buddhist scriptures in various languages. Search a verse to explore its origins, interpretations, and related texts. Engage with the community by sharing insights and learning from others through sheets and topics.
✦ Pecha Editor
Pecha Editor is a web-based editor that allows scholars to load data—along with its annotations—from the OpenPecha API and modify it directly within the interface.
 Architectural Considerations
Architectural Considerations
✦ Tech Stack
- Programming Language: Python
- Backend Framework: Firebase
- API: RESTful API for accessing and managing data
- Data Storage: Google Cloud Storage for storing texts, annotations, and metadata
✦ System Diagram

System Architecture of Pecha Platform Using Firebase Services
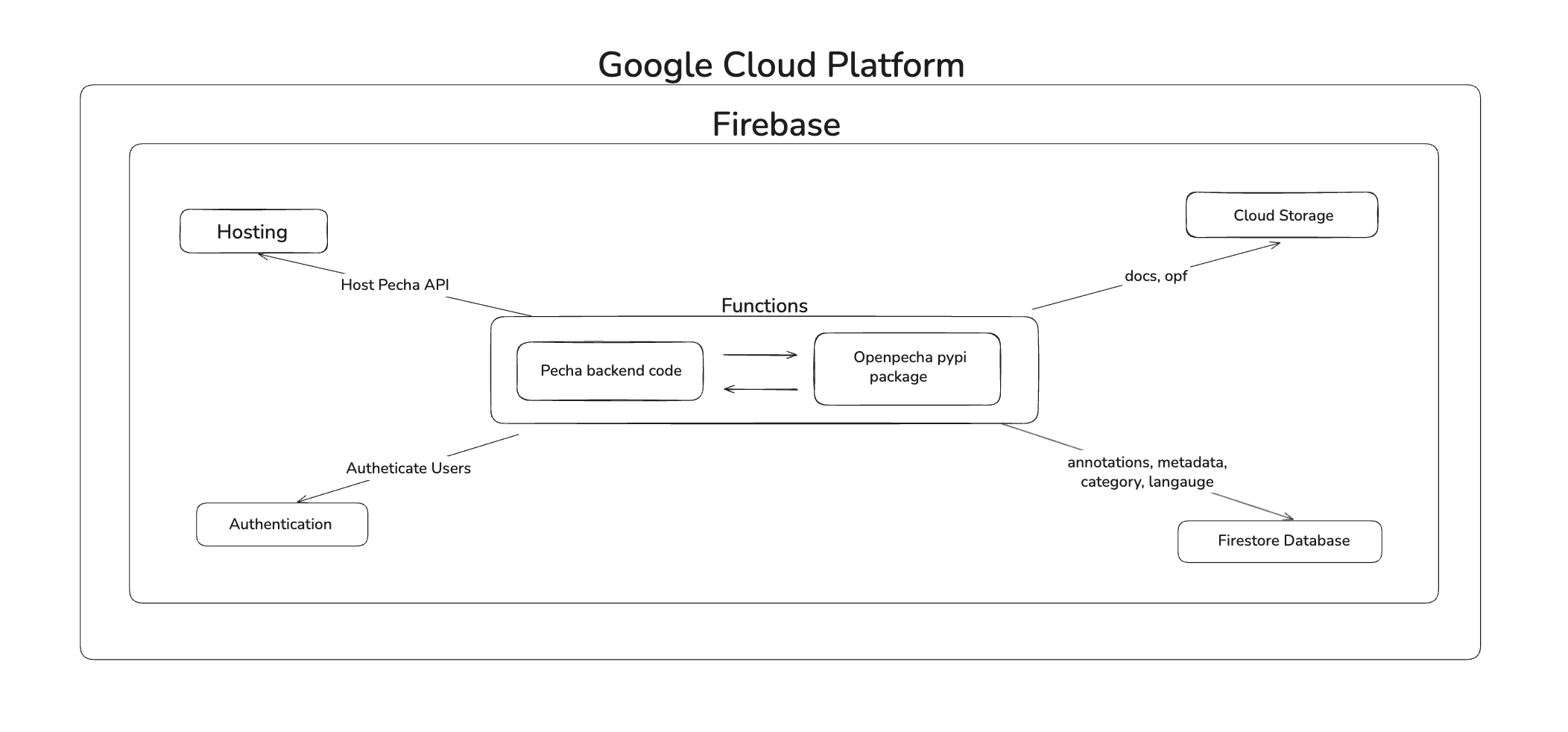
✦ Security & Privacy
-
Data Protection: All user-contributed content and personal information will be protected using industry-standard encryption both in transit and at rest. We implement secure data storage practices to prevent unauthorized access to texts and annotations.
-
API Security: All API endpoints will use secure authentication tokens with rate limiting to prevent abuse. We implement proper access controls to ensure only authorized users can upload or modify content.
-
Data Versioning and Recovery: We implement comprehensive version control for all texts and annotations, maintaining complete revision history with rollback capabilities.
✦ Dependencies
-
Firebase: Used for hosting backend code, managing authentication, and storing metadata and annotations in Firebase’s database.
-
Toolkit Package: A core Python package for parsing, annotating, and converting data into the OpenPecha format (OPF), including STAM-based annotation structures.
-
Google Cloud Console: Used for storing data sources such as DOCX files, OpenPecha-formatted data, and their version history.
✦ Scalability & Maintenance
-
Open Source Development Model: Our toolkit is maintained as a public GitHub repository, enabling community-driven development through branching and pull requests. This collaborative approach ensures continuous improvement and reduces maintenance burden on core developers.
-
Modular Package Architecture: The toolkit is distributed as a Python pip package, providing clean separation between core functionality and backend implementation. This modular design allows for independent updates and easier integration with external systems.
-
Robust Development Workflow: Our OpenPecha backend maintains separate development and production branches. All changes undergo comprehensive testing in the development environment before being merged to production, ensuring system stability and reliability.
-
Platform-Agnostic Data Models: We design our data models to be as technology-agnostic as possible, avoiding vendor lock-in and ensuring easy migration or integration with future platforms and technologies. This approach protects our investment and maintains long-term flexibility.
-
Expanding Data Support: We are committed to supporting a growing range of Buddhist data, including not only texts but also images, audio recordings, and other relevant formats. This expansion allows us to preserve and share Buddhist knowledge in its diverse forms.
 Participants
Participants
✦ Working Group Members
Key contributors with their responsibilities.
✦ Stakeholders
Other teams or external partners with a vested interest.
✦ Point of Contact
Tashi Tsering | tashitsering@esukhia.org
 Project Status
Project Status
✦ Current Phase
We are currently developing comprehensive documentation for our Toolkit package to ensure that any product consumer can effectively parse data from the Pecha API and seamlessly integrate it into their own products.
In parallel, we are transitioning to integrate the Toolkit’s OCR parser with the OpenPecha backend, enabling the storage and processing of all BDRC data.
✦ Milestones
- ✓ Toolkit package with capability to parse root texts, translations, and commentary DOCX files, including full integration with the OpenPecha backend.
- ✓ Toolkit functionality to parse and process Buddhist Digital Resource Center (BDRC) data, enabling comprehensive import of existing digitized Buddhist literature..
- ✓ Complete OpenPecha backend development to securely store pechas and their associated annotations.
- ✓ Implement end-to-end publishing pipeline to automatically deploy processed pechas to the pecha.org website, making texts publicly.
✦ Roadmap
- Q3 2025: Launch a fully functional API with comprehensive documentation that allows users to freely access Buddhist data along with its annotations.
- Q4 2025: Ingest and store the complete BDRC dataset in the OpenPecha storage infrastructure.
- Q1 2026: Enhance the API with advanced search capabilities and integrate Retrieval-Augmented Generation (RAG) features.
- Q2 2026: Expand data support to include not only textual data but also audio and image formats.
 Meeting Times
Meeting Times
✦ Regular Schedule
E.g., Monday every two weeks at 2:30 PM IST via Google Meet where we do our sprint planning.
✦ Meeting Notes
Link to running minutes, past discussions, or decisions.
 What We’re Working On
What We’re Working On
We maintain a public task board with all active issues and discussions.